:format(webp)/f/138645/1920x1080/f9dd96f43e/hero-background-desert-town-drifters.png)


The hidden optimisation in network games...
Posted on
Optimisation in network games isn't always about the speed of servers. Our Head of Client Engineering at Hutch, Peter takes a deep dive into how our data is serialised and parsed, and talks next level optimisation when using JSON. Over to Peter!
:format(webp)/f/138645/6720x4480/4d81823e30/hutch-london0810.jpg)
When optimising a network connected game, it’s quite natural to look for opportunities to improve the speed at which the server handles network requests and also into the speed at which the client handles the data and loads the relevant assets. The developers at Hutch have instinctively applied optimisation to these areas of our games and have achieved a lot to minimise our data load, group requests together and reduce the number of network requests in general.
However, the one optimisation that was previously overlooked was into how our data is serialised and parsed. We use JSON data to communicate between the server and client because it’s simple, human readable, fairly lightweight (compared to say, XML), and most importantly highly ubiquitous. Both server and client find it very easy to communicate with JSON.
The common issue with JSON data in C# applications is that a lot of basic JSON libraries cast the received JSON data into a string and then break it down into string elements for each key/value pair. This obviously leads to a high number of allocation as strings in C# are immutable, so each time a string is created it allocates more memory. There are libraries that are more efficient at reducing this allocation and lots of alternative serialisation methods that might be faster and more efficient.
In investigating possible optimisations for our boot times, I saw that simply deserialising the data from a single server request on boot was taking 1295ms and allocating 13.6mb of memory. I set about investigating what options there were into improving and optimising the way we handled our data.
Firstly I needed to set some requirements:
Ideally network data remains human readable for easy debugging
Data should ideally use less bandwidth and not more.
There should be libraries for client and server to easily read and send the data
Should allocate less memory in both serialisation and deserialisation
Should serialise and deserialise data faster
Should not require significant work to implement or maintain
Needs to be able to support complex C# objects, including: enums, inherited classes, generics with constraints and null objects
Ideally should be extensible to support any types or custom formatting/resolving that we need in the future.
Candidates for serialisation:
Msgpack (https://github.com/msgpack/msgpack)
Utf8Json (https://github.com/neuecc/Utf8Json)
We’ll benchmark against Newtonsoft Json.NET, which was our previous system for handling data.
Other developers have already done some benchmarking of some of these options. Here’s a chart taken from the Utf8Json page linked above:
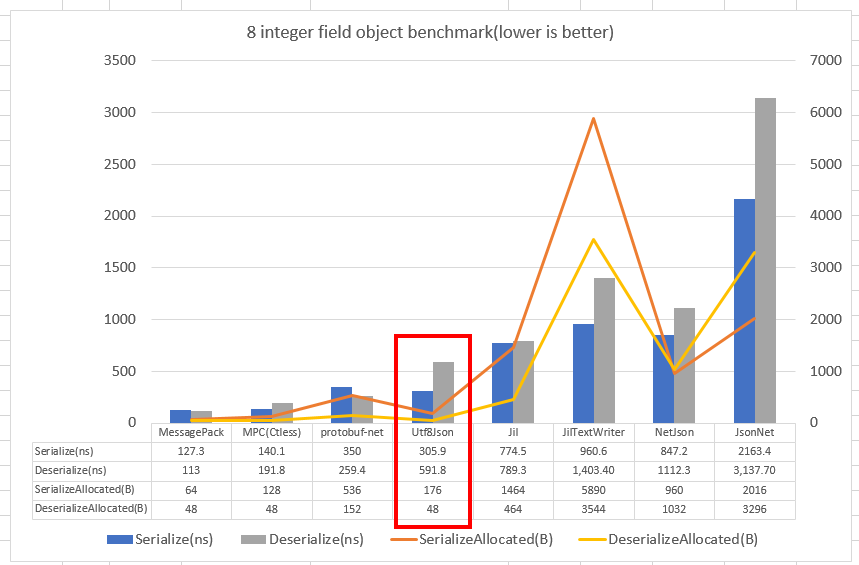
Based on these benchmarks, I expected that all the candidates should perform better than Json.NET, but MessagePack looks to be the fastest.
To narrow them down, I ran a suite of tests to determine their memory footprint and speed, comparing engineering time, suitability, ease of use and extensibility.
I wrote six separate benchmarks for our C# application:
The speed and memory allocated serialising 10,000 small non-complex objects.
The speed and memory allocated serialising 10,000 large complex objects.
The functionality to serialise a very complex object that meets all our requirements.
Here’s an example of the benchmark object used:

I intended on testing all the candidates and benchmarks on an Android phone for realistic results. However, I encountered an immediate problem. In switching on IL2CPP in Unity, it was causing some of the libraries to throw exceptions and fail to run the benchmark.
In investigating, I realised that the problem was that a core component of most libraries that perform dynamic serialization/deserialization is the System.Reflection.Emit namespace. It generates metadata which can be used to identify object types at runtime. Unfortunately, IL2CPP has no support for System.Reflection.Emit.
Therefore the serialization/deserialization library must either generate the type resolvers + formatters ahead of time (AOT), or simply work without referencing the System.Reflection.Emit library.
With the small setback, I attempted to generate the resolvers and formatters ahead of time. It would require our development teams to have to modify their build processes slightly and they would need to remember to generate the resolvers and formatters in advance, but seemed like a small cost for the benefits we could gain in our network handling performance.
Unfortunately Jil neither worked with IL2CPP, nor did it offer an AOT compilation option, rendering it unfortunately unsuitable for the benchmarks. Given that it also didn’t appear to support generics, I decided that it wasn’t worth pursuing further unless the other alternatives proved fruitless also.
I was able to generate the code for messagepack and Utf8Json ahead of time, but in doing so, I realised that Msgpack would require a lot of engineering time to get working, despite its high performance. Our games use a very high number of different types of objects in their networking communication and having to manually add key attributes to all the types and custom serialisation/deserialisation logic to the more complex types would cause a significant amount of work for the teams. Msgpack also lacked human readability, which I ideally wanted to maintain
Utf8Json supported most of the requirements for complex types, but lacked the ability to generate code for generics with constraints. Fortunately the code was open source, quite easy to extend and very quick to build and test. I branched the git repository and added the following functionality to Utf8Json:
Detection for specific attributes on a type eg. [HutchAOTSerialisable] or [HutchAOTDeserialisable] to mark the object type for the ahead-of-time generation of formatters and resolvers respectively.
Support for generics with constraints.
The code generation would detect generic types and find the type of object within the generic and all the possible base types of that class and generate all possible resolvers.
In the situation where a type contained multiple generics, the code generation would build a matrix of all possible combinations and build all relevant resolvers or formatters.
After this was done, with plenty of testing, I finally managed to build the benchmarks to device and test.
The Results
These results are for a benchmark which serialises and deserialises a complex benchmark object 10,000 times. The code for the serialisation benchmark is below. It uses a random seed to ensure that objects are different each request and no caching happens (just in case some of the libraries did some clever optimisation).

And now for the big reveal, the results:

Memory allocation was reduced from 248.3MB to 31MB. A reduction of 87.5%.
Processing time was reduced from 6845ms to 858ms. A reduction of 87.4%.
Incredibly promising results, all that was left to do was to implement it in a Hutch game.
As I mentioned earlier, in one of our games a single particularly heavy network request that happened as part of the boot process was taking 1295ms and allocating 13.6mb of unnecessary memory. After implementing our new Utf8Json serialisation, the same request took 315ms and allocated only 1.3mb! The boot flow actually sends several requests, with each one showing similar performance gains.
This seemingly small change saved over a second of loading screen for every user who booted our app. Across a whole session we probably saved upwards of 20 seconds of processing time and allocated over 100MB less memory. We didn’t lose readability of our JSON data, we didn’t create any server engineering work, the client workflow is largely the same and it supports all the complex types we need.
:format(webp)/f/138645/2172x2066/d0e1b41148/gi22_winner_g.png)
:format(webp)/f/138645/2577x2568/42abc2e3a0/bptw21_winner_logos_circle-3.png)
:format(webp)/f/138645/500x500/331c7ca7e9/best-places-to-work-2020.png)